In the last post the basic architecture of the application-level code was developed:
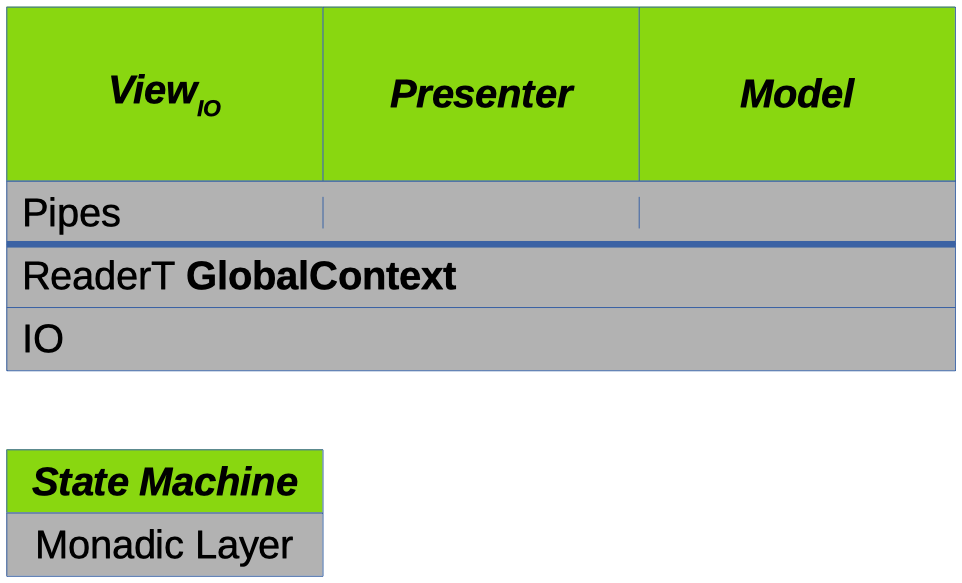
In this post we'll dive a bit deeper into the state-machines then go over some of the pragmatic refinements made to the architecture and to the implementing code.
State-Machines
This application has a few distinct phases of operation:
- Idle for when the application is waiting to be told what file to load by the user
- One of various loading stages while the file is loaded and processed
- Editing for when the user is able to interact with the audio data
In order to keep the code coherent and manageable, the architectural components -- specifically the Model and the Presenter -- were broken down into different states corresponding to each of these operational phases, thus becoming state-machines.
The states of these machines are comprised of one or more functions each, with each machine then being a set of mutually-recursive functions.
As the codebase grew, many things were done to keep the management of these functions tenable. This is what we'll discuss in this post.
State Monad
Many of the functions in the View and Presenter components rely on shared state, but to pass that state around as a discrete argument to each function would have been burdensome. Therefore, I decided to try adding state monad-transformers to the mix to carry the state along under the hood.
My desire was to have distinct states/transformers for each of the components, to keep their concerns separate. At first I wasn't sure if this was possible; it turns out it is, though there is a little catch.
My first attempt at adding state monad-transformers looked like this:
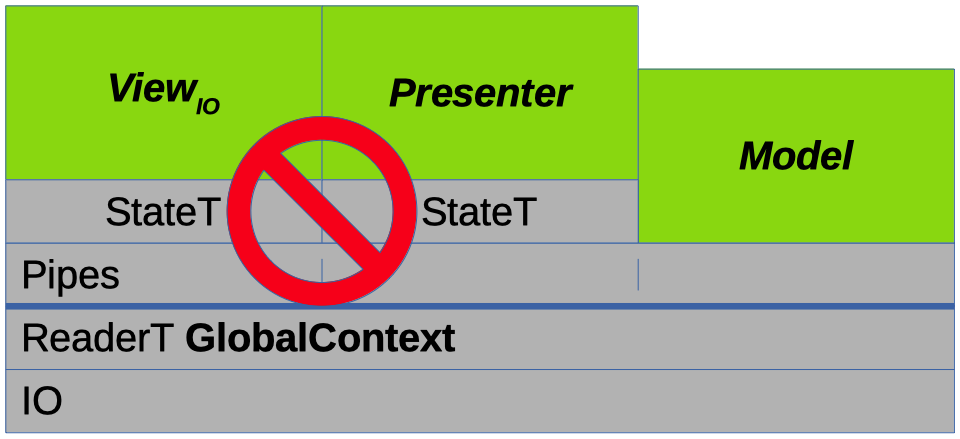
As you might guess, it didn't work so well.
While the type-system happily allowed this and the program ran, memory consumption ballooned like mad.
I would like to be able to explain the technical reasons behind this, and I think I have an intuitive idea, but my monad-transformer-fu is not up to snuff. (As I mentioned in an earlier post, I'm still learning and this project was experimental for me.)
At first I was worried about what this would mean for the feasibility of the project, but after a little digging a solution presented itself (what a blessing!): the pipes library has facilities for running other monad transformers beneath it, so all I had to do was swap the order of the transformers in the type definitions and run the state monads with evalStateP from Pipes.Lift instead of evalStateT.
The architecture now looks like this:
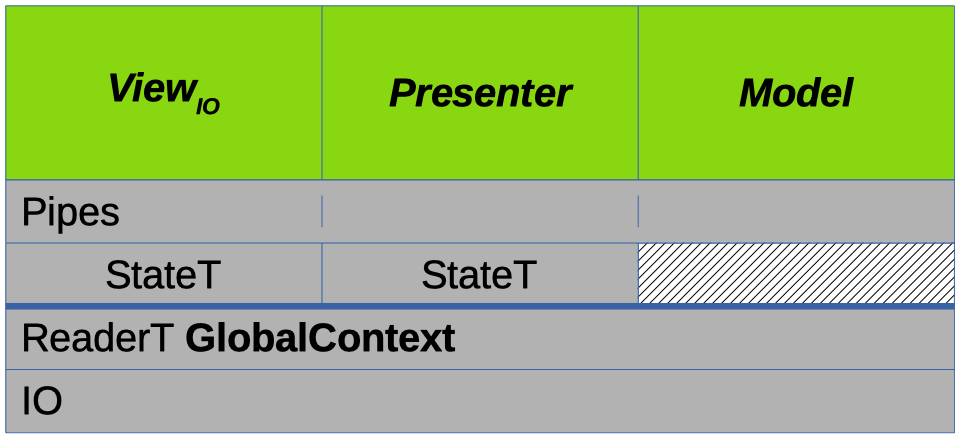
and works just fine.
Alleviating Boilerplate
In the post on abstraction I outlined some type-classes that were made to abstract from IO operations and configuration locations.
For a function to use these type-classes they have to be declared as constraints in the type-signature of the function. With a state-machine consisting of many functions, each calling the others, and each function requiring multiple type classes, that led to a lot of constraint declarations.
This became quite annoying, especially when adding a new constraint to the mix -- all of the functions of a machine had to be updated with the new constraint.
To alleviate this I thought I might make a single type-class inheriting from all the others I needed for a machine, like so:
class
( HasSettings r
, HasStyle r
, HasProgramName r
, MonadFix m
, MonadReader r m
, Operation m o
) => PresenterStateConstraint m r o where {}
and then specify that single class on each of the machine's functions.
As I started to implement this, though, I saw that it would require me to make an instance of the conglomerate type-class for the App type, and that seemed like unnecessary boilerplate since App already implemented each of the inherited type-classes individually.
After a bit of research, I found one could create class synonyms: type-class instances not tied to any particular type! This meant I could avoid having to declare a specific instance for App -- App wouldn't even have to know anything about the state-machine type-classes -- and just have a general synonym instead.
Here's the synonym instance for the above type-class, and it lives in the same module as the declaration, just beneath it in the code:
instance
( HasSettings r
, HasStyle r
, HasProgramName r
, MonadFix m
, MonadReader r m
, Operation m o
) => PresenterStateConstraint m r o where {}
(Note that we're declaring an instance here rather than a class as above; other than that the code is the same.)
So now when a type-class has to be added to or removed from a machine, it's a change of as little as two lines!
If you'd like to use class-synonyms you'll need to enable the UndecidableInstances language extension, and IIRC the FlexibleInstances extension as well.
Message-Type Refactoring
Communication between the different MVP components in this application is done via message passing, with each inter-component message channel having its own data-type:
- Presenter Input for View→Presenter messages
- Presenter Output for Presenter→View messages
- Model Input for Presenter→Model messages
- Model Output for Model→Presenter messages
On the receiving side, these messages are processed in case expressions; e.g.:
case input of
Message1 field1 field2 field3 ->
...
Message2 field1 field2 ->
...
Message3 field1 field2 field3 field4 field5 field6 field7 ->
...
...
With a lot of message constructors to process, these expressions were prone to being long and/or repetitive -- both undesirable traits. So when they became burdensome to work with, I decided to refactor.
In my time programming in Haskell I've noticed that the structure of the data-types one declares has a pretty noticeable influence on the code that gets written, a phenomenon in evidence here.
As part of the refactoring of this code some adjustments were made to a couple of the message data-types so that the code that handled them would be cleaner; we'll discuss these changes in the following sub-sections.
Data Segregation: Reducing Churn
One of the things I wanted to do when refactoring message handling in the Presenter was to separate the longer bodies of case expression matches out into discrete functions.
These functions would have to be given the data from the message type-constructors the cases matched against, and that meant a potential for code churn: if a data-field was added to or removed from a message constructor, then the pattern in the case expression for that constructor would have to be adjusted and the type-signature and argument list of the processing function would have to change as well.
During times of high fluidity this became annoying, so I took all the data-fields out of the constructor and put them into a separate product type, then made the constructor carry just that type. That way, when adjustments were made to the product type, only the producer and the consumer of that data would have to change, but all of the code in-between could stay the same, thus reducing the churn.
Generalized Messages: Eliminating Redundancy
Many of the messages sent to the Model from the Presenter invoke transformations on internal model data. Initially, I'd had separate message type-constructors corresponding to each of these transformations, with the message-handling code in the Model calling the appropriate transform functions.
As the number of transforms grew, more and more message type-constructors were required and the code to do the message handling became quite redundant: each of the messages was essentially the arguments for a transformation function sans the internal model data, so all of the calls looked similar:
case input of
DoTransform1 arg1 arg2 ->
update modelData (transform1 arg1 arg2)
DoTransform2 arg1 arg2 arg3 ->
update modelData (transform2 arg1 art2 arg3)
DoTransform3 arg1 ->
update modelData (transform3 arg1)
DoTransform4 arg1 arg2 ->
update modelData (transform4 arg1 arg2)
...
So, to refactor, I replaced all the different transform message type-constructors with one or two generalized constructors that accepted a function to run on the internal model data instead:
case input of
DoTransform f ->
update modelData f
...
This simplified the processing code and as a bonus I could use function composition to pass multiple transforms in as a single message, which came in handy when I started really implementing the UI logic.
Future Refinement
One style of Haskell development is to use the type system to express as much as possible about what a program does, leaving less chance for an error to sneak through in the data.
I would like to use this style in the state-machines to express what inputs a particular state is expecting and exclude all the other inputs that might be acceptable to other states. However, I don't know if the pipes library is able to accomodate this. It's something I may attempt in the future, though, in one way or another.